
pandas를 효율적으로 사용하는 방법(1/2)
python을 이용하여 데이터 분석을 하는 사람이라면 pandas는 가장 많이 애용하는 라이브러리 중 하나일 것이다. pandas는 쉽고 빠르지만 최적화를 진행하지 않고 사용하다가는 memory overflow가 발생하거나 크지 않은 데이터를 처리하면서 하염없이 작업이 끝나기를 기다리는 자신을 발견할지 모른다. 이 글에서는 pandas에서 메모리를 효율적으로 사용할 수 있는 방법에 대하여 설명한다.
pandas에서 데이터를 처리하다보면 적게는 수백 개부터 많게는 수천만, 수억 개 이상의 데이터를 처리해야 한다. 당연한 이야기이겠지만 이 데이터들은 각자 메모리 공간을 차지하므로 너무 많은 메모리를 차지하면 memory overflow가 발생하거나 비효율적인 계산을 하게 된다. 이를 방지하기 위해 메모리 공간 사용을 최소화하도록 다양한 방법을 활용할 수 있다.
데이터 전처리 역할 분담
pandas는 데이터 저장소로부터 기초 데이터(raw data)를 불러와서 새로운 데이터로 가공하여 결과물을 만들어내는 작업에 많이 사용한다. 하지만, 기초 데이터의 양이 많을수록 엄청난 IO 부담과 시간 비용이 늘어나게 되고, 이러한 데이터를 가공할 때 많은 리소스를 필요로 하게 된다. 상황에 따라 pandas에서 기초 데이터를 이용하여 다양한 결과물을 만들어낼 수 있지만, 무조건 기초 데이터를 이용하여 처리를 할 필요는 없다. 오히려, aggreate가 가능한 빅데이터 플랫폼을 이용하고 있다면, 기본적인 전처리는 pandas에서 직접하는 것보다 해당 플랫폼에서 처리하여 제공받는 것이 빠르고 효율적일 경우가 많다. (보통 처리 속도도 차이가 나지만, 많은 양의 IO 때문에 데이터를 가져오는 시간이 꽤 소요되는 경우가 많다.)
또한, 빅데이터 플랫폼에서 전처리하는 과정 중에 일부 feature engineering을 해줄 수 있기 때문에 pandas에서 사용해야 하는 메모리를 최소화할 수 있고, 계산 또한 빠르게 처리할 수 있다. 만약, 회사에서 직접 대용량 데이터 처리를 위한 빅데이터 플랫폼을 구축하기 부담스럽다면, 구글의 BigQuery나 Arm의 TreasureData 와 같은 서비스를 이용하는 것을 추천한다.
데이터 형식 최적화
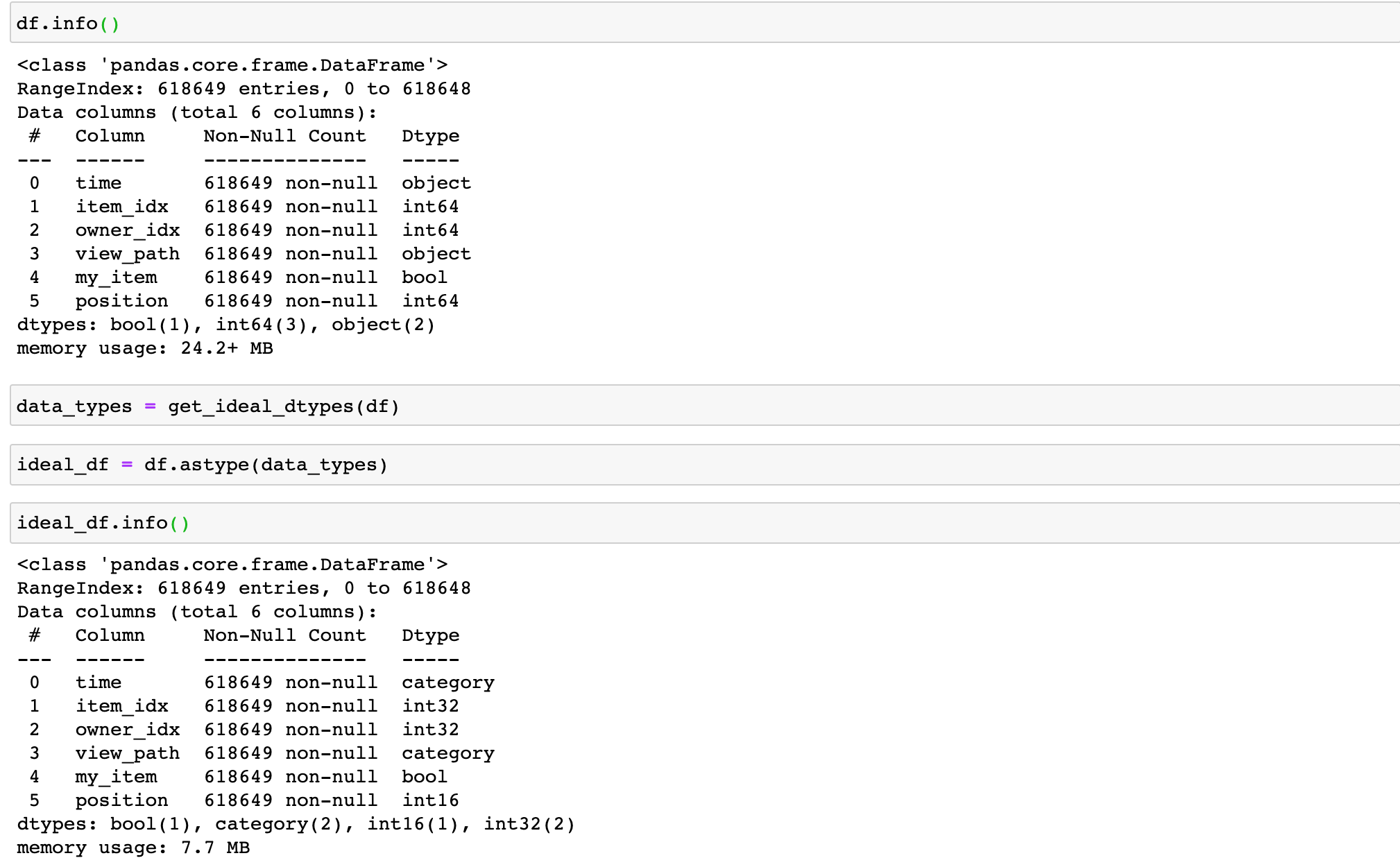
pandas에서 처리할 수 있는 데이터 형식(dtype)은 pandas dtypes 설명 링크를 참고하면 된다. 링크의 내용을 살펴보면, pandas에서 지원하는 데이터 형식에는 numpy에서 지원하는 float, int, bool, datetime64 이외에도 category, string, object 형식 등 다양한 데이터 형식이 있는데 데이터 형식은 종류에 따라 가질 수 있는 값의 범위가 다르고 당연히 메모리 사용공간에 차이가 있다. 따라서, 처리하고자 하는 데이터가 가지고 있는 값의 범위에 따라 최적화된 데이터 형식을 지정해주어야 불필요한 메모리 사용량을 줄일 수 있다.
유사한 데이터 형식을 최적화하기 위해서는 아래의 코드를 참고하면 된다.
def get_ideal_dtypes(df):
ideal_dtypes = dict()
for column in df.columns:
dtype = df[column].dtype
if dtype != object:
c_min = df[column].min()
c_max = df[column].max()
# 숫자형 데이터 형식 최적화
if str(dtype)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
ideal_dtypes[column] = 'int8'
elif c_min > np.iinfo(np.uint8).min and c_max < np.iinfo(np.uint8).max:
ideal_dtypes[column] = 'uint8'
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
ideal_dtypes[column] = 'int16'
elif c_min > np.iinfo(np.uint16).min and c_max < np.iinfo(np.uint16).max:
ideal_dtypes[column] = 'uint16'
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
ideal_dtypes[column] = 'int32'
elif c_min > np.iinfo(np.uint32).min and c_max < np.iinfo(np.uint32).max:
ideal_dtypes[column] = 'uint32'
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
ideal_dtypes[column] = 'int64'
elif c_min > np.iinfo(np.uint64).min and c_max < np.iinfo(np.uint64).max:
ideal_dtypes[column] = 'uint64'
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
ideal_dtypes[column] = 'float16'
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
ideal_dtypes[column] = 'float32'
else:
ideal_dtypes[column] = 'float64'
else:
n_unique = df[column].nunique()
# 값의 종류가 n개 미만일 경우에만 category 형식으로 최적화
if n_unique > n:
ideal_dtypes[column] = 'object'
else:
ideal_dtypes[column] = 'category'
return ideal_dtypes
위의 코드에서는 숫자형 데이터 형식은 각 컬럼의 min, max값으로 범위를 구하여 최적의 데이터 형식을 찾아준다. 그리고 object 데이터 형식이 특정 값들로 반복될 때, category 데이터 형식을 권장한다. 이 방법을 이용하면, 아래와 같이 24MB의 데이터를 7MB까지 줄일 정도로 큰 효과를 볼 수 있다.
코드화
데이터 형식 최적화가 최적화된 데이터 형식을 찾아내는 것이었다면, 코드화는 사람이 알아보기 쉬운 값을 컴퓨터가 사용하기 용이한 형태로 변경하는 작업이다. 쉬운 예로, 성별, 지역 등과 같이 구분되어지는(discrete) 문자열(String) 을 0,1과 같은 숫자로 변경하는 과정을 들 수 있다. 이 방법은 메모리 최적화를 진행할 수 있는 방법 중 가장 쉽게 사용 메모리를 줄일 수 있는 방법이다.

위와 같이 category 형식과 코드화는 메모리 크기가 동일하므로(둘다 int8) 가독성이 좋은 category를 이용하는 것이 더 낫긴 하다.
불필요한 데이터 필터링
pandas에서 사용하는 데이터들을 살펴보면 불필요한 값들이 남아있는 경우가 많다. 이런 불필요한 데이터들은 필터링을 진행하고 데이터 처리를 하는 것이 좋다. 일례로 데이터를 처리하고나서 필요없어진 데이터나 비정상적인 값들로 판단되어 처리대상이 아닌 데이터가 있는 경우 제거하는 것이 좋다. 또한, 부분적으로 필요한 열이나 행 데이터만 가져와서 처리를 한다거나, python generator를 이용하여 원하는 크기만큼 데이터를 가져와서 처리할 수도 있다. 이는 데이터를 제공한 도메인에 대한 관련 지식이 있는 사람이 처리를 하는 것이 바람직하다.
다음 글에서는 pandas를 효율적으로 사용하는 방법 중 효율적인 데이터 처리 방식에 대해 설명하고자 한다.