
KEDA를 활용한 스케일링 스케쥴링하기
이 글에서는 쿠버네티스 환경에서 다양한 조건의 파드 스케일링을 위해 HPA(Horizontal Pod Autoscaler) 대신에 KEDA(Kuberneters Event-Driven Autoscaler)를 활용하는 것에 대해 살펴보고자 한다.
HPA의 문제점
실 서비스에서 서비스 부하에 따라 적절하게 어플리케이션 서버 숫자를 증감하는 것(scaling)은 안정적인 서비스 운영에 반드시 필요한 기능이다. 클라우드 서비스 이용이 활발하지 않고 모놀리틱(monolithic)한 서비스로 운영하던 시절에는 서버를 증감하는 것이 쉽지 않았고, 이를 자동화하는 것은 더더욱 쉽지 않았다. 다행히도 도커와 같은 컨테이너 서비스, 그리고 수 많은 컨테이너를 효율적으로 관리하기 위한 쿠버네티스가 등장했고, 이제는 많은 서비스들이 두 기술을 활용하고 있다.
쿠버네티스에서는 동일한 스펙의 여러 개의 파드를 하나의 서비스처럼 묶어줄 수 있는 디플로이먼트나 스테이트풀셋이 존재한다. 또한, HPA를 통해 서비스 부하에 따라 적절히 파드를 줄이거나 늘려 스케일링이 가능하다. 이 때 서비스 부하를 정량적으로 체크할 수 있도록 CPU 사용량, 초당 패킷 처리량, 초당 요청 처리 수 등을 활용할 수 있다.
이렇게 HPA를 이용하면 기본적인 워크로드 스케일링은 가능하지만, 특정 시간에 트래픽이 몰려서 미리 스케일링을 예약하거나 여러 파드 스케일링 조건을 조합해서 사용하는 등 디테일한 스케일링 전략을 적용하기 쉽지 않다.
KEDA(Kubernetes Event-Driven AutoScaler)
앞서 언급한 HPA가 가진 문제를 해결하기 위해 KEDA를 활용할 수 있다. KEDA는 Kubernetes event-driven autoscaler의 줄임말로, 말 그대로 쿠버네티스 상에서 사용할 수 있는 이벤트 중심의 오토스케일러이다.
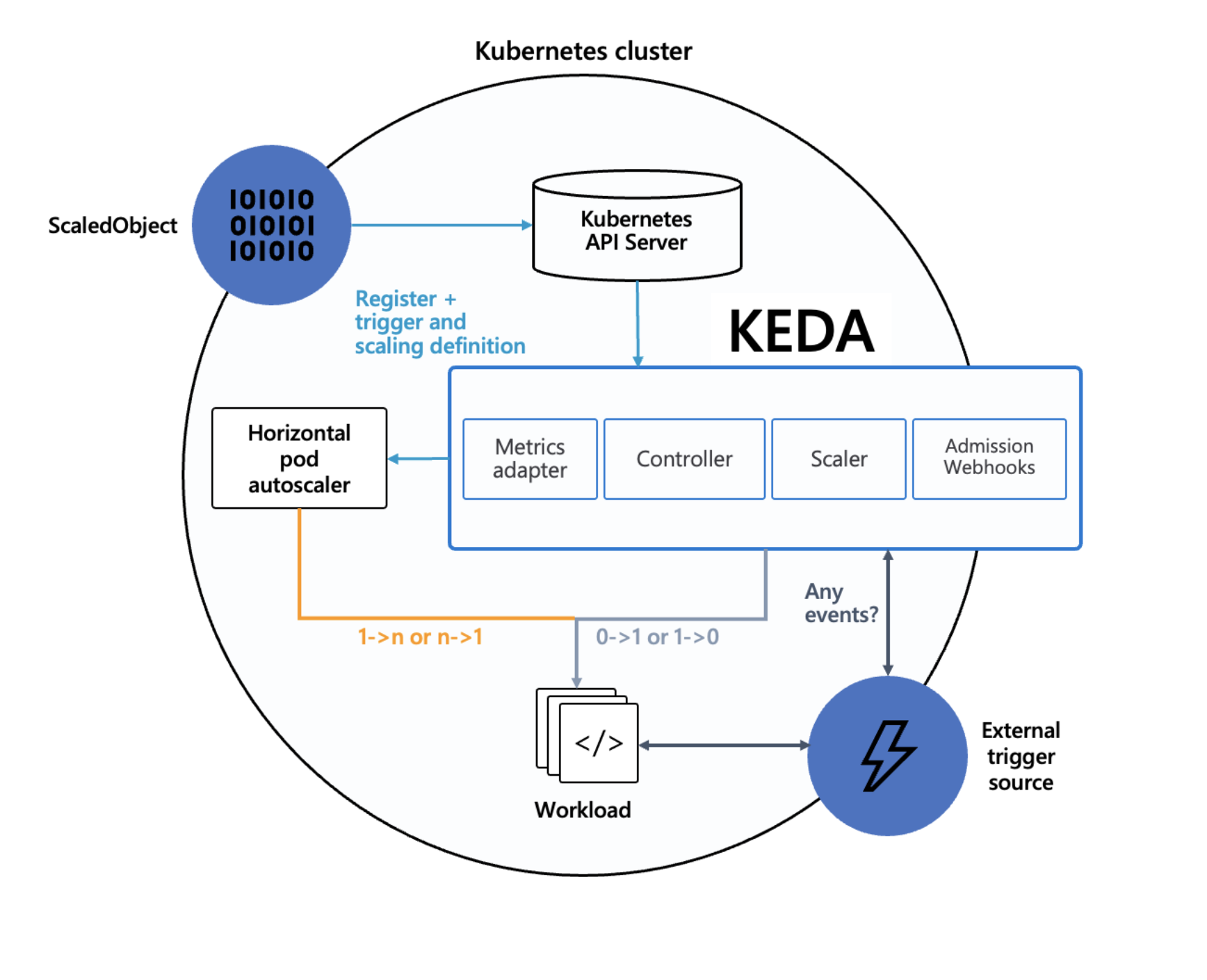
KEDA의 기본 구조는 위 그림과 같은데, 기본적으로 KEDA에서 제공하는 ScaledObject를 이용하여 스케일링을 할 때 활성화된 스케일러 중 원하는 레플리카 개수가 가장 큰 개수로 현재 워크로드의 수를 결정하고, 이를 HPA가 반영한다. 유심히 봐야 할 것은 내부적으로 HPA가 존재한다는 점이다. 즉, KEDA를 사용할 때는 HPA는 별도로 선언하지 않아야 하고 만약 HPA를 선언한다면 의도치 않게 충돌이 발생할 수 있다.
KEDA는 HPA와 비교했을 때 아래와 같은 장점을 가지고 있다.
1. 다양한 스케일러 제공
현재(2024년 1월 25일) 기준 64개의 스케일러가 존재하여 다양한 조건의 스케일링 전략을 적용할 수 있다. 기본적인 CPU, 메모리 기준을 이용한 스케일링 뿐 아니라 Cron 같은 스케쥴 기반의 스케일링도 가능하다. 여러 스케일러 중 특정 서비스 메트릭의 조건을 스케일링에 활용할 수 있어 다양한 외부 서비스와 워크로드 스케일링이 연동될 수 있다.
2. 여러 개의 스케일러를 조합하여 디테일한 스케일링 처리 가능
다양한 스케일러가 존재하기 때문에, 여러 스케일러를 조합하여 복잡한 스케일링 전략을 취할 수 있다.
가령, 오후 10시부터 최소 파드의 수를 10대로 유지하고, CPU 평균 사용량이 3800m가 넘는다면 2대씩 증설한다와 같은 스케일링 전략을 취할 수 있다.
3. HPA의 상위 호환 기능 제공
HPA와 거의 유사한 형태로 선언할 수 있어 별다른 추가 학습이 필요하지 않다. 또한 HPA 에서 설정할 수 없었던 minReplicaCount를 0로 설정할 수 있고, 일부 디테일한 설정들이 추가되었다.
4. ScaledObject와 ScaledJob 제공
기본적으로 ScaledObject 내에 사용할 트리거와 관련 옵션들을 전략에 맞게 선언하여 HPA를 제어할 수 있다. 반면에 긴 수행시간을 가지는 스케일링을 처리하기 위한 오브젝트로 ScaledJob도 제공한다. 이는 쿠버네티스의 Job 레벨에서 워크로드 스케일링을 제어할 수 있게 되어 동시에 병렬 수행할 수 있고 스케일링 시간이 오래 걸리는 일부 사례에 견고한 전략을 세울 수 있다. 이렇게 2가지 오브젝트를 사용자 편의에 맞게 활용하여 스케일링을 처리할 수 있다.
Cron 스케일러 활용
이제 KEDA에 살펴보았으니 실제로 Cron 스케일러를 통해 스케일링에 스케쥴을 적용해보는 과정을 살펴보도록 하자.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
...
spec:
maxReplicas: 20
minReplicas: 2
scaleTargetRef:
...
...
metrics:
- type: Resource
resource:
name: cpu
target:
type: AverageValue
averageValue: 1800m
위와 같은 HPA 명세는 최소 파드의 개수를 2개, 최대 파드의 개수를 20개로 지정하고, CPU 평균 사용량이 1800m가 넘었을 때 새로운 파드를 추가하자라는 스케일링 전략을 명세하고 있다.
우리는 위와 같은 명세를 최소 파드와 최대 파드의 숫자는 유지하되, 오전 7시와 오전 10시에 잠시 동안 최소 파드의 개수를 4개로 보장하고 싶다고 변경하고자 한다.
apiVersion: keda.sh/v1alpha1 # <-- keda api로 변경
kind: ScaledObject # <-- ScaledObject 활용
metadata:
...
labels:
...
spec:
minReplicaCount: 2 # <-- minReplica -> minReplicaCount
maxReplicaCount: 20 # <-- maxReplica -> maxReplicaCount
scaleTargetRef:
...
...
triggers:
- type: cpu
metricType: AverageValue
metadata:
value: "1800m"
- metadata: # <-- cron trigger 추가
desiredReplicas: "4" # <-- 원하는 레플리카 수
end: 10 7 * * * # <-- trigger 종료 시각
start: 45 6 * * * # <-- trigger 시작 시각
timezone: Asia/Seoul # <-- timezone 설정
type: cron # <-- trigger 타입
- metadata:
desiredReplicas: "4"
end: 10 22 * * *
start: 45 21 * * *
timezone: Asia/Seoul
type: cron
위 ScaledObject 명세 중 cron trigger의 조건을 보면, start와 end에 각 이벤트가 수행될 시간을 cron expression으로 정의한 것을 볼 수 있다. 이는 각 시간은 파드가 올라오는 시간이 존재하기 때문에 여유있게 10~15분의 간격을 둔 것이다. 이제 기존 HPA를 제거하고 위에서 선언한 ScaledObject를 추가하면 된다.
마치며
지금까지 HPA를 대신하여 KEDA를 활용해서 스케일링을 스케쥴링하는 예시를 살펴보았다.
KEDA는 HPA를 상위 호환하는 이벤트 중심의 AutoScaler로, 스케쥴링이나 다양한 외부 서비스 메트릭을 이용하여 원하는 워크로드의 스케일링을 제어할 수 있다.
단순 스케일링이 아닌 디테일한 스케일링 제어를 원한다면 KEDA를 사용해보도록 하자.