
클래스 불균형(Class imbalance) 문제 개선하기
실 데이터로 머신러닝 모델을 학습하다보면 일부 클래스의 데이터가 다른 클래스에 비해 상대적으로 많은 클래스 불균형(Class imbalance) 문제를 자주 마주하게 된다. 이러한 클래스 불균형 문제는 편향된 모델을 학습하게 되어 높은 성능을 보장하기 어렵기 때문에 적절하게 해결해주어야 한다.
이 글에서는 클래스 불균형 문제를 개선할 수 있는 방법들을 다양한 각도에서 살펴보도록 한다.
클래스 불균형(Class imbalance)란?
클래스 불균형이란, 모델 학습에 사용되는 데이터가 특정 클래스에 치중되어 있어 편향된 모델을 학습하게 되는 문제를 말한다.
실제 환경에서 습득한 데이터로 학습할 경우 클래스 불균형은 빈번하게 발생할 수 있어 이를 처리하는 방법을 알고 있는 것이 좋다.
또한, 클래스 불균형 문제를 해결할 수 있는 방법은 다양하지만, 무작정 여러 방법을 사용하게 되면 오히려 모델 성능을 더 악화시킬 수 있으므로 상황에 따라 적절한 전략을 선택하여 모델의 성능을 향상시키는 것이 중요하다. 실제로 적절한 전략으로 학습된 모델은 학습하지 않은 새로운 데이터를 만나도 일반화되어 좋은 성능을 보여줄 수 있다.
이러한 클래스 불균형을 해결할 수 있는 여러 가지 방법들에 대해 알아보자.
재샘플링(Re-sampling)
재샘플링(Re-sampling)은 수집된 데이터를 클래스 특성에 따라 다시 샘플링하는 방법이다. 소수 클래스 데이터를 늘리거나, 다수 클래스의 데이터를 줄여서 클래스별 데이터 크기 차이를 최소화하여 편향된 모델을 학습하는 것이 주 목적이다.
1. 과소샘플링(Under-sampling)
이 방법은 다수 클래스에서 일부 샘플을 제거하여 클래스 간 균형을 맞추는 방법이다. 다수 클래스를 가진 데이터가 일부 제거되므로 학습 시간도 빨라지고 메모리도 적게 사용할 수 있다는 장점이 있다.
다만, 학습에 활용할 수 있는 데이터를 무작위로 버리는 셈이 되므로 전반적인 학습 성능에 떨어질 수 있다. 또한, 보통 소수 클래스의 개수에 최대한 맞추기 때문에 클래스간 데이터 수의 차이가 너무 크지 않거나 소수 클래스의 데이터 개수가 충분할 때 사용하는 것이 바람직하다.
2. 과대샘플링(Over-sampling)
이 방법은 과소샘플링과는 반대로 소수 클래스의 샘플을 증가시켜 클래스 간 균형을 맞추는 방법이다. 다만, 단순히 복제하는 것은 특정 샘플에 편향된 모델을 학습을 유도하므로 소수 클래스 샘플을 합성하여 새로운 샘플을 생성하는 합성 샘플링(Synthetic Sampling) 방법을 많이 사용한다.
그 중에서도 Synthetic Minority Over-sampling Technique(이하, SMOTE)가 가장 많이 알려져있다.
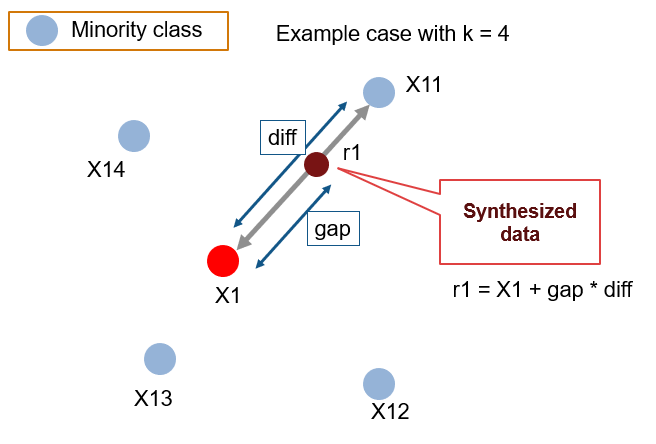
SMOTE는 위와 같이 두 샘플 사이에 각 feature의 보간(Interpolation)을 새로운 샘플에서 부여하는 방법으로 kNN(K-nearest neighbor)로 구해진 k개의 근접 샘플간의 보간을 활용한다.
이 방법을 사용하면, 소수 클래스의 샘플을 늘리면서도 단순 복제가 아닌 유사 샘플을 늘리게 되어 클래스 불균형과 오버 피팅 문제를 동시에 해결할 수 있다.
다만, kNN을 기반하므로 데이터 셋이 클수록 계산 비용이 증가하고 이상치에 대해서도 합성을 진행하게 된다는 문제점이 있으므로, 소수 클래스의 샘플이 해당 클래스의 데이터 분포를 대변할 수 있으나 단지 수집된 개수가 적은 경우에 사용할 때 효율적이라고 볼 수 있다.
과대샘플링에는 SMOTE 이외에도 ADASYN, Borderline-SMOTE 등 여러 방법이 있으므로 필요하다면 관련된 방법들을 찾아보도록 하자.
앙상블
앙상블 기법은 다양한 모델을 결합하여 불균형한 클래스를 더 잘 학습하는 방법으로, 다양한 모델을 함께 사용함으로써 오버피팅을 줄이고 각 모델의 약점을 보완해서 정확도를 향상시킬 수 있다. 특히 소수 클래스에 더 중점을 두는 모델을 포함시키는 전략이 유효할 수 있다. 앙상블 학습은 모델의 다양성을 확보하고 예측 성능을 향상시킬 수 있어, 클래스 불균형을 해결하는 데 효과적인 방법 중 하나다.
다만 여러 모델을 조합해야 하므로 비용이 많이 들고, 모델의 예측 결과에 대한 이유를 분석하기 어렵다는 단점이 있다.
클래스별 가중치 조정
가중치 조절은 클래스 간의 불균형을 해결하기 위한 또 다른 효과적인 방법으로, 다수 클래스와 소수 클래스의 샘플에 서로 다른 가중치를 부여하여 모델이 소수 클래스에 더 많은 주의를 기울이도록 하는 방법이다. 이를 통해 모델은 소수 클래스를 잘못 분류했을 때 더 큰 패널티를 받게 되어, 불균형한 데이터에서도 어느 정도 밸런스를 갖춘 모델을 학습할 수 있다.
이 방법은 학습 데이터 내 각 클래스마다 다른 가중치를 할당할 수 있다는 점을 활용하기 때문에 간단하게 시도할 수 있지만, 모델이 여전히 다수 클래스를 향해 편향될 가능성이 높아 클래스 불균형이 매우 심한 경우에 효과적이지 않을 수 있다.
또한, 각 클래스에 적절한 가중치를 찾는 것이 어렵고 이를 위한 추가적인 실험이 필요할 수 있다.
손실 함수(loss function) 변경
손실 함수(loss function)은 모델의 예측 값과 실제 값 간의 차이를 측정하는 함수로, 모델이 예측한 결과가 실제 결과와 얼마나 다른지 나타내는 지표로 사용된다. 이러한 특성 때문에 클래스 불균형 문제에서 손실 함수를 어떻게 정의하느냐에 따라 모델의 성능을 더욱 개선시킬 수 있다.
Focal loss
focal loss는 학습 모델에서 클래스 불균형 문제를 다루기 위해 설계된 손실 함수로 Focal Loss for Dense Object Detection이라는 논문에서 Lin에 의해 소개되었다.
focal loss의 목적은 교차 엔트로피 손실(cross-entropy loss)과 유사하지만 쉬운 샘플에 덜 집중하여 전반적인 분류 성능을 향상시키는 것에 있다.
\[FL(p_t) = -(1-p_t)^{\gamma}{\log}(p_t)\]위 focal loss의 수식을 보면, 기존 교차 엔트로피 손실에 \((1-p_t)\)의 수식을 추가하여 쉬운 샘플에 대한 손실을 줄임으로써, 어려운 샘플에 대한 손실에 집중하게 된다. 또한, 이것의 정도를 \({\gamma}\)를 활용하여 조절할 수 있다.
아래 코드는 PyTorch에서 구현한 focal loss 예제 코드이다.
class FocalLoss(nn.Module):
def __init__(self, gamma: float = 2.0, weight: Optional[torch.Tensor] = None, ignore_index: int = 0):
super().__init__()
self.gamma = gamma
self.weight = weight
self.ignore_index = ignore_index
def forward(self, x: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
log_pt = F.cross_entropy(
x, target, weight=self.weight.to(x.device), reduction="none", ignore_index=self.ignore_index
)
pt = torch.exp(-log_pt)
loss = (1.0 - pt) ** self.gamma * log_pt
return loss.mean()
Asymmetric loss
asymmetric loss는 앞서 설명한 focal loss의 문제점을 해결하면서 보다 더 극단적으로 클래스 불균형 문제를 다루는 손실 함수이다.
Asymmetric Loss For Multi-Label Classification라는 논문에서 제안된 방법으로, 이름에서도 알 수 있듯이 여러 클래스에 대해 비대칭적인 계산을 통해 클래스 불균형 문제를 해결한다.
focal loss는 정답에 가깝게 예측한 샘플(쉬운 샘플)은 다수 클래스, 소수 클래스 상관 없이 무조건 영향을 줄인다. 그래서 가뜩이나 적은 소수 클래스에 기여도가 더 줄어들어서 전반적인 성능 저하를 유발할 수 있다는 단점이 있다.
이러한 문제를 해결하기 위해 asymmetric loss는 두 가지 개선점을 제시한다.
Asymmetric focusing
우선 positive와 negative를 위한 loss를 아래와 같이 따로 정의하고, 각각의 \(\gamma_+\) 와 \(\gamma_-\)를 별도로 설정한다.
\[L_+=(1-p)^{\gamma_+}\log(p)\] \[L_-=p^{\gamma_-}\log(1-p)\]이 때 \(\gamma_-\)를 \(\gamma_+\)보다 크게 만들어서 수가 적은 positive 샘플의 기여도를 줄이지 않도록 한다.
Asymmetric probability shifting
asymmetric focusing보다 더 강력하게 쉬운 negative 샘플을 제어하기 위해 loss에 들어가는 확률의 일부를 강제로 조정한다.
\[p_m=\max(p-m, 0)\]수식을 보면, m(margin) 보다 작은 확률값을 가지면 강제로 0의 확률값을 가지도록 한다.
적절한 m 값을 지정하면 모든 negative 샘플의 기여도는 m만큼 줄어들게 되고, m 미만의 확률값은 0으로 치환되므로 쉬운 negative 샘플의 기여도는 0이 되어, 클래스 불균형 문제를 조금 더 강력하게 제어할 수 있게 된다.
아래 코드는 PyTorch에서 구현한 asymmetric loss의 예제 코드이다.
class AsymmetricLoss(nn.Module):
def __init__(
self,
weight: Optional[torch.Tensor] = None,
gamma_pos: float = 0.0,
gamma_neg: float = 1.0,
margin: float = 0.2,
eps: float = 1e-6,
):
super().__init__()
self.weight = weight
self.gamma_pos = gamma_pos
self.gamma_neg = gamma_neg
self.margin = margin
self.eps = eps
def forward(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> torch.Tensor:
p_neg = torch.clamp(torch.sigmoid(y_pred) - self.margin, min=self.eps)
logit = y_pred * y_true + (torch.log(p_neg) - torch.log(1 - p_neg)) * (1 - y_true)
bce_loss = F.binary_cross_entropy_with_logits(
logit, y_true, weight=self.weight.to(x.device), reduction="none"
)
p_t = torch.exp(-bce_loss)
gamma = self.gamma_pos * y_true + self.gamma_neg * (1 - y_true)
loss = bce_loss * ((1 - p_t) ** gamma)
return loss.mean()
마치며
클래스 불균형은 머신 러닝 모델의 성능을 저하시킬 수 있는 중요한 문제이다. 다양한 방법을 통해 클래스 불균형 문제를 해결할 수 있지만, 데이터셋의 특성과 문제의 복잡도에 따라 적합한 방법을 선택해야 한다.
특히 클래스 가중치를 조정하거나 손실 함수를 변경하는 것은 별도의 샘플링 과정이나 별도의 노력을 하지 않아도 되므로 클래스 불균형 문제에 적절히 활용해보는 것을 추천한다.