
elasticsearch에서 nori, ngram tokenizer를 동시에 활용하기
elasticsearch는 최근 가장 많이 사용되고 있는 검색 및 분석 엔진 서비스로 빠른 속도, 쉬운 확장성과 같은 장점때문에 많이 사용되고 있다. 보통 검색엔진으로 사용하는 경우, tokenizer를 이용하여 token을 색인하는데, 어떤 tokenizer를 활용하냐에 따라 검색의 방향과 품질에 정해진다. 이 중 nori tokenizer는 잘 알려진 한글 tokenizer로써, 사용자 사전과 함께 사용하면 좋은 성능을 보인다.
하지만, nori tokenizer나 사용자 사전에서 인식하지 못하는 형태소나 부분적으로 포함된 키워드가 있을 경우 검색 결과에서 볼 수 없는 문제가 있다. 이 글에서는 nori tokenizer와 ngram tokenizer를 같이 활용하여 검색 품질을 높일 수 방법에 대해 알아보고자 한다.
문제점 및 개선방향
그동안 개발하고 있는 서비스에서는 elasticsearch에 nori tokenizer를 활용했다. (nori tokenizer에 약 20만개의 사용자 사전과 동의어, 불용어 사전을 붙여 사용했다.) 이 방법은 사전 정보가 잘 구성이 되어 있을 때는 성능이 좋지만 사전이 부족하거나 정제되지 않는 키워드가 많은 경우 검색이 잘 되지 않는 문제가 있었다. (사용자가 직접 컨텐츠를 생산하는 경우, 정제되지 않은 키워드가 포함될 가능성이 높으므로 예측하지 못한 단어 사용이 늘어나 문제가 발생될 확률이 높다.)
이를 개선하기 위해 아래의 조건을 만족하면서 LIKE 검색과 유사하게 동작할 수 있는 방법을 찾아야 했다.
- nori tokenizer로 색인하는 방법과 병행할 수 있는 방법이어야 한다.
- 검색 속도 및 성능에 지장이 있어서는 안된다.
우선, 기존 nori tokenizer로 색인하여 검색하는 방법의 성능이 어느정도 보장이 되었기 때문에 기존의 성능은 유지하면서 개선할 수 있어야 한다. 또한, 새로운 방법을 적용한다고 해도 검색엔진 속도나 성능에 문제가 생기지 않아야 한다.
새로운 필드 생성 그리고 wildcard 쿼리
우선, 첫 번째 조건을 만족하기 위해 가장 먼저 떠오른 아이디어는 wildcard 쿼리를 사용하는 것이었다. wildcard는 sql의 LIKE 쿼리와 같이 특정 키워드가 포함된 모든 결과를 찾을 수 있어서 원하는 동작을 할 수 있다고 생각했다.
테스트를 위해 애국가 앞 부분을 nori tokenizer를 이용하여 추출된 결과는 아래와 같다.
curl -XPOST http://localhost:9200/test/_analyze?pretty -H 'content-type: application/json' -d '
{
"analyzer": "nori_analyzer",
"text": "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세"
}
{
"tokens" : [
{
"token" : "동해",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "물",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 1
},
{
"token" : "백두",
"start_offset" : 5,
"end_offset" : 7,
"type" : "word",
"position" : 3
},
{
"token" : "산",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 4
},
{
"token" : "마르",
"start_offset" : 10,
"end_offset" : 12,
"type" : "word",
"position" : 6
},
{
"token" : "닳",
"start_offset" : 14,
"end_offset" : 15,
"type" : "word",
"position" : 8
},
{
"token" : "하느",
"start_offset" : 18,
"end_offset" : 20,
"type" : "word",
"position" : 10
},
{
"token" : "님",
"start_offset" : 20,
"end_offset" : 21,
"type" : "word",
"position" : 11
},
{
"token" : "보우",
"start_offset" : 23,
"end_offset" : 25,
"type" : "word",
"position" : 13
},
{
"token" : "우리",
"start_offset" : 28,
"end_offset" : 30,
"type" : "word",
"position" : 16
},
{
"token" : "나라",
"start_offset" : 30,
"end_offset" : 32,
"type" : "word",
"position" : 17
},
{
"token" : "만세",
"start_offset" : 33,
"end_offset" : 35,
"type" : "word",
"position" : 18
}
]
}
이렇게 nori tokenizer로 색인한 문서 중 백두가 포함된 검색결과를 얻기 위해 wildcard로 검색하면 아래와 같다.
curl -XGET http://localhost:9200/test/_search?pretty -H 'content-type: application/json' -d '
{
"query": {
"wildcard": {
"nori": {
"value": "*백두*"
}
}
}
}
'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"text" : "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세"
}
}
]
}
}
그렇다면 다음의 예를 살펴보자.
curl -XGET http://localhost:9200/test/_search?pretty -H 'content-type: application/json' -d '
{
"query": {
"wildcard": {
"nori": {
"value": "*닳도*"
}
}
}
}
'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
위 예를 보면, 본문에 닳도록이라는 문자열이 있어서 닳도라는 검색어로 검색될 것으로 생각할 수 있지만 이미 닳이라는 token으로 분해되어 색인이 되었기 때문에 원하는대로 동작하지 않는다. 이 예시를 통해 wildcard를 사용하더라도 기존 필드는 유지하고 새로운 필드에 다른 tokenizer를 이용하여 색인을 하는 것이 바람직하다고 느꼈다. 색인하는 필드를 늘리게 되면 저장공간을 더 많이 필요로 하고 색인 속도가 느려진다는 단점이 있지만, nori를 이용하여 색인하는 기존 필드는 변하지 않기 때문에 검색 결과가 줄어서 품질이 떨어질 확률은 없다고 생각했다. (물론, 원하지 않는 검색결과가 노출되어 precision이 감소할 수 있지만 recall이 올라갈 것이기 때문에, 검색어 상태에 따라 검색해야 할 필드를 지정하면 큰 문제가 되지 않을 것이라고 판단했다.)
또한, wildcard를 *질의어*와 같이 쓰게 되면 원하는 키워드를 찾기 위해 반복하는 과정이 늘어날 수 있다고 경고하고 있기 때문에 다른 방법을 찾아야 했다.
ngram tokenizer 추가
새로운 필드에 색인을 한다고 해도 wildcard와 같이 쿼리 레벨에서 처리할 수 없다면, LIKE 검색과 유사하게 색인할 수 있는 tokenizer가 필요했다. 이러한 문제를 해결할 수 있는 ngram tokenizer가 있는데, ngram은 자연어 처리를 조금이라도 해보았다면 한 번쯤 들어봤을 것이다.
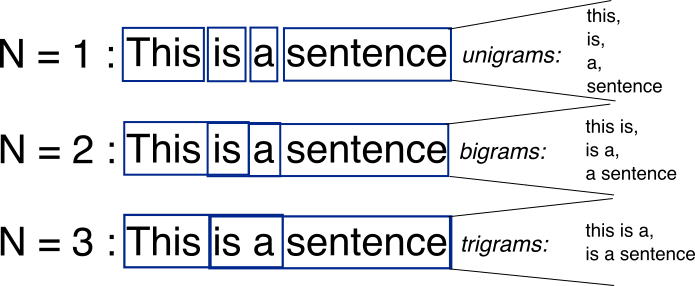
위 그림을 보면 ngram에 대해 쉽게 이해할 수 있다. ngram은 n개의 인접 단어를 추출하여 학습이나 분석에 사용하는데, n=1인 경우 첫 번째 항목처럼 unigram이라 불리우고 각 단어 1개씩을 추출한다. n=2인 경우는 bigram이라 하고 this is, is a와 같이 2개씩 묶어서 추출한다. 이렇게 추출된 ngram은 인접한 단어 패턴을 분석하여 문서의 종류를 분류하거나 문서를 조합할 때 쓰인다. ngram을 활용한 tokenizer는 term 레벨에서 ngram을 추출하게 되는데, 단어가 아닌 문자 단위로 추출한다.
curl -XPUT http://localhost:9200/test -H 'content-type: application/json' -d '
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"type": "custom",
"tokenizer": "my_ngram"
}
},
"tokenizer": {
"my_ngram": {
"type": "ngram",
"min_gram": 2,
"max_gram": 2,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
}
'
curl -XPOST http://localhost:9200/test/_analyze?pretty -H 'content-type: application/json' -d '
{
"analyzer": "ngram_analyzer",
"text": "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세"
}
'
{
"tokens" : [
{
"token" : "동해",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "해물",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 1
},
{
"token" : "물과",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 2
},
{
"token" : "백두",
"start_offset" : 5,
"end_offset" : 7,
"type" : "word",
"position" : 3
},
{
"token" : "두산",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 4
},
{
"token" : "산이",
"start_offset" : 7,
"end_offset" : 9,
"type" : "word",
"position" : 5
},
{
"token" : "마르",
"start_offset" : 10,
"end_offset" : 12,
"type" : "word",
"position" : 6
},
{
"token" : "르고",
"start_offset" : 11,
"end_offset" : 13,
"type" : "word",
"position" : 7
},
{
"token" : "닳도",
"start_offset" : 14,
"end_offset" : 16,
"type" : "word",
"position" : 8
},
{
"token" : "도록",
"start_offset" : 15,
"end_offset" : 17,
"type" : "word",
"position" : 9
},
{
"token" : "하느",
"start_offset" : 18,
"end_offset" : 20,
"type" : "word",
"position" : 10
},
{
"token" : "느님",
"start_offset" : 19,
"end_offset" : 21,
"type" : "word",
"position" : 11
},
{
"token" : "님이",
"start_offset" : 20,
"end_offset" : 22,
"type" : "word",
"position" : 12
},
{
"token" : "보우",
"start_offset" : 23,
"end_offset" : 25,
"type" : "word",
"position" : 13
},
{
"token" : "우하",
"start_offset" : 24,
"end_offset" : 26,
"type" : "word",
"position" : 14
},
{
"token" : "하사",
"start_offset" : 25,
"end_offset" : 27,
"type" : "word",
"position" : 15
},
{
"token" : "우리",
"start_offset" : 28,
"end_offset" : 30,
"type" : "word",
"position" : 16
},
{
"token" : "리나",
"start_offset" : 29,
"end_offset" : 31,
"type" : "word",
"position" : 17
},
{
"token" : "나라",
"start_offset" : 30,
"end_offset" : 32,
"type" : "word",
"position" : 18
},
{
"token" : "만세",
"start_offset" : 33,
"end_offset" : 35,
"type" : "word",
"position" : 19
}
]
}
위 예를 살펴보면, bigram(2gram)을 추출하여 동해, 해물, 물과와 같이 2개씩 묶여 색인한 결과를 볼 수 있다. (질의어 패턴을 보았을 때 bigram만으로 충분히 LIKE 검색과 유사하게 사용할 수 있다고 생각했다. 적용하고자 하는 검색 서비스 특성에 따라 unigram(1gram), trigram(3gram)과 같은 다양한 ngram을 활용할 수 있다.)
curl -XGET http://localhost:9200/test/_search?pretty -H 'content-type: application/json' -d '
{
"query": {
"multi_match" : {
"query": "닳도",
"fields": [ "ngram" ]
}
}
}
'
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"nori" : "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세",
"ngram" : "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세"
}
}
]
}
}
이렇게 ngram tokenizer를 이용하면 색인된 문서를 단순 쿼리로 검색할 수 있다.
또한, 아래와 같이 nori, ngram 필드 모두에 대해서도 원하는 검색결과를 얻을 수 있다.
curl -XGET http://localhost:9200/test/_search?pretty -H 'content-type: application/json' -d '
{
"query": {
"multi_match" : {
"query": "백두",
"fields": [ "nori", "ngram" ]
}
}
}
'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.8630463,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.8630463,
"_source" : {
"nori" : "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세",
"ngram" : "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세"
}
}
]
}
}
지금까지 nori tokenizer와 ngram tokenizer를 활용하여 사전 및 LIKE 검색을 동시에 처리하는 방법에 대하여 알아보았다.
- nori tokenizer 색인
- 별도의 필드에 ngram tokenizer를 이용하여 색인
- 두 필드에 대해 multi match query 사용
간단히 정리하면, 위 3가지 과정을 거치면 쉽게 적용할 수 있다.
단, 이 방법은 무조건적인 성능 개선이 아니기 때문에(recall은 증가시키고 precision을 감소시킬 수 있기 때문에) 검색 서비스의 특성을 고려하여 반영하는 것이 바람직해보인다.