
광고 소재 최적화를 위한 MAB 활용기
뚜렷한 수익모델이 없는 서비스가 쉽게 돈을 벌 수 있는 방법 중 하나는 광고를 유치하여 수익을 창출하는 것이다. 하지만, 광고를 집행하는 것이 생각처럼 쉽지는 않다. 광고주는 자신의 광고가 효율적으로 집행되고 지불한 금액 이상으로 광고 효과를 보기 원하기 때문이다. 이러한 광고주의 요구사항을 만족하기 위해 광고를 직접 집행하는 서비스나 광고 대행 플랫폼에서는 정해진 광고 영역에서 최적의 광고를 노출하기 위해 다양한 장치를 마련한다. 이 글에서는 MAB(multi armed bandit) 알고리즘을 활용하여 제한된 광고 영역에서 광고 효율을 높이기 위해 광고 소재를 최적화했던 경험을 공유한다.
광고 소재 최적화
광고주는 자신의 광고가 많이 노출되고 많은 관심을 받기 원한다. 하지만, 광고 지면이나 기간은 한정되어 있기 때문에 무분별하게 광고를 노출한다면 높은 CTR(Click through rate, 클릭율)을 기대하기 어려울 것이다. 그러므로 광고를 효율적으로 노출하기 위해 광고가 노출될 사용자 층을 선정하거나 더 효율이 좋은 광고 소재를 책정해야 한다. 물론 노련하고 숙달된 광고주는 자신의 광고를 어떤 사용자 층에 노출해야 할지, 어느 소재가 더 효율적으로 사용자들의 관심을 끌지 알 수도 있지만 정확성을 보장하기 어렵고 대부분의 광고주는 판단조차 내리기 어려워한다.
이러한 문제를 해결하기 위해 광고를 전문적으로 집행하는 서비스는 노출할 사용자의 연령, 나이와 같은 개인 정보나 iOS, Android와 같은 사용 OS 등을 광고주가 직접 선택하거나 광고 제목이나 이미지 배너와 같은 광고 소재 중 최적의 광고 소재를 선정하여 광고를 집행할 수 있도록 한다.
광고 소재를 최적화할 때는 여러 가지 후보 소재를 노출하고 광고에 대한 사용자 행동 피드백을 분석하여 최적의 광고 소재를 선정하게 되며, 일정 기간동안 최적화된 광고 소재는 동일한 노출을 하더라도 더 많이 클릭을 유도할 수 있는 광고를 집행할 수 있게 도와줄 것이다.
위의 설명을 보면 광고 소재 최적화는 여러 광고 소재에 대하여 A/B 테스트를 진행하는 것으로 볼 수 있다. A/B 테스트는 매우 간단하면서도 훌륭한 평가 수단이 되지만 무작정 A/B 테스트를 진행하는 것은 생각보다 쉽지 않다. A/B 테스트를 얼마동안의 기간에 걸쳐 진행해야 하는지 언제 최적화된 광고가 수렴되는 것인지 직접 개발을 하려면 모호한 부분이 많다. 이런 모호한 부분을 쉽고 강력하게 해결할 수 있는 방법인 MAB를 소개하고자 한다.
MAB(multi-armed-bandit)
multi armed bandit(이하 MAB)는 각기 다른 보상율을 갖는 여러 개의 슬롯머신(광고) 중에서 어떤 대상에 시도를 해야 가장 높은 보상을 받을 수 있는지에 대한 문제를 해결하기 위한 알고리즘이다. 이는 보상율이 더 높은 대상을 찾기 위한 탐색(exploration)과 탐색한 지식을 기반으로 최적의 선택을 하는 활용(exploitation)과의 tradeoff에서 더 나은 선택을 하기 위해 만들어진 알고리즘이라고도 할 수 있다. MAB를 살펴보기 위해 다음과 같은 가정을 해보자.
- 각기 다른 당첨율을 갖는 N개의 슬롯머신이 있다.
- 한 번에 한 개의 슬롯머신을 시도할 수 있다.
- 동작한 슬롯머신의 당첨 여부는 바로 알 수 있다.
이 경우 가장 높은 당첨금을 얻을 수 있는 전략은 무엇일까?
greedy
가장 쉽게 생각해볼 수 있는 방법은 N개의 슬롯머신을 한 번씩 시도해보고 그 결과를 활용하는 것이다. 이 방법은 간단하지만 너무 적은 횟수의 탐색으로 전체를 일반화하기 때문에 성급한 일반화의 오류를 범할 가능성이 높다.
ε-greedy
다음으로 생각해볼 수 있는 방법은 ε(입실론)이라는 하이퍼 파라메터를 정의하고 1-ε의 확률로 지금까지 가장 당첨율이 좋았던 슬롯머신을 선택하고 ε의 확률로 임의의 슬롯머신을 선택하는 방법이다. 이 방법을 ε-greedy 알고리즘이라 하는데 이 방법은 최적의 슬롯머신을 선택할 때 더 탐색할지 탐색된 내용을 활용할지의 기준을 ε라는 값으로 정할 수 있다는 점에서 의미가 있다. 하지만, ε에 따라 부족한 탐색 지식을 기반으로 선정해야 할 수도 있고, 오랜 기간이 지나 수익율이 좋은 슬롯머신을 알면서도 임의의 슬롯머신을 시도해야 하는 문제가 생길 수 있다.
UCB(upper confidence bound)
위 두 가지 방법은 현재의 당첨율만을 이용하여 처리하기 때문에 한계가 있다. 이를 해결하기 위해 현재까지 당첨율이 가장 좋은 슬롯머신을 선택하되, 과거의 시도와 그 결과에 기반한 값을 같이 고려하여 슬롯머신을 선택할 수 있다. 이를 UCB(upper confidence bound) 알고리즘이라 하고 다양한 방법으로 과거의 관측값을 구하게 된다. 그 중 가장 간단한 방법인 UCB1에서는 아래의 수식을 이용하여 최적의 슬롯머신을 찾게 된다.
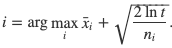
가운데 xi는 i번째 슬롯머신에 대해 현재까지 평균 당첨율을 의미한다. 오른쪽 수식이 과거의 관측값을 의미하는데 t는 현재 시간(즉, 현재까지 슬롯머신을 시도한 횟수), ni는 i번째 슬롯머신을 실행한 횟수를 의미한다. 이 수식대로라면 특정 슬롯머신이 적게 실행된 경우 오른쪽 가중치가 커지게 되서 다양한 슬롯머신에게 기회를 줄 수 있고, 시간이 흐를수록 t값이 커지지만 log를 취하기 때문에 가장 성능이 좋은 슬롯머신에 수렴하게 될 것이다.
UCB는 현재까지 당첨율과 과거의 이력을 이용하여 좋은 정확도를 보인다고 알려져있다. 하지만, 제로베이스에서 바로 값을 얻을 수 없고 초기 시도 값이 존재해야만 값을 구할 수 있다는 단점이 있다.
TS(thompson sampling)
thompson sampling(이하 TS)를 살펴보기 앞서 베타 분포에 대해 살펴보도록 하자.
베타 분포는 두 개의 매개변수 a, b에 대해 [0, 1]에서 정의되는 연속확률분포로써 아래와 같은 수식으로 구할 수 있다.
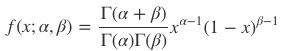
위 수식을 보면 베르누이 분포를 갖는 사건에 대하여 a, b의 값에 따라 지속적으로 변화하는 연속확률분포를 구할 수 있다. 위 수식에서 확률밀도함수인 감마함수 Γ은 아래와 같이 정의된다.
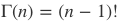
위 수식대로 a, b에 따라 계산되어진 베타 분포는 아래와 같은 모습을 갖는다.
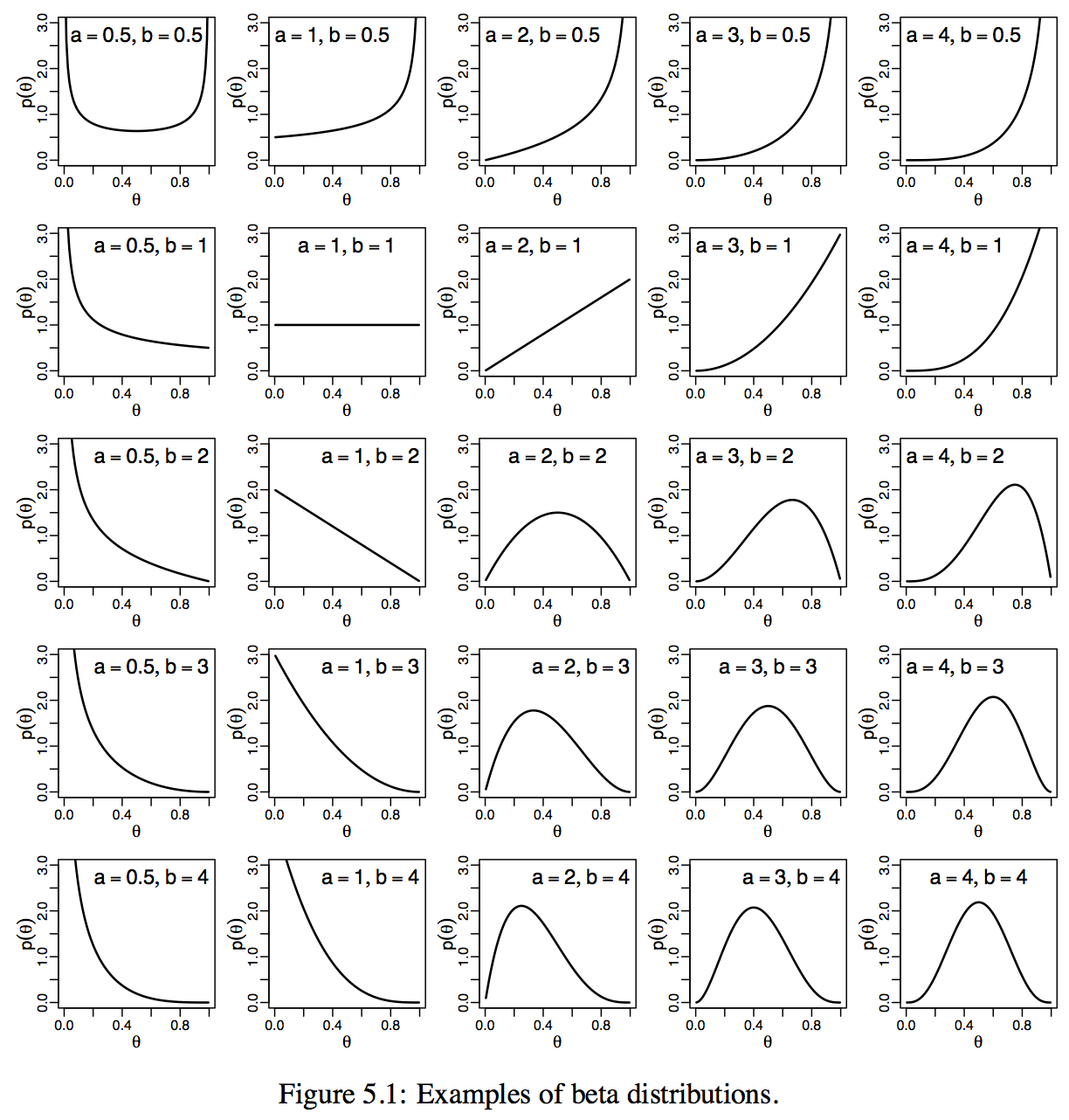
위 샘플들을 살펴보면 a, b의 값에 따라 지속적으로 연속확률분포가 변화하는데, a와 b의 합이 커질수록 특정 x값을 중심으로 표준편차가 줄어들고 y값이 커진다. 또한 a가 커질수록 더 큰 x값으로 분포의 중심이 이동하게 되고 b가 커질수록 더 작은 x값으로 분포의 중심이 이동하게 된다.
즉, a를 성공한 횟수, b를 실패한 횟수로 가정했을 때 성공이던 실패던 시도를 할수록 점점 특정 확률로 수렴하게 되고, a가 커지면 성공할 확률이 높아지며, b가 커지면 실패할 확률이 높아지는 연속확률분포를 구할 수 있다.
이러한 베타 분포의 특성을 활용하면 아래와 같이 가장 적절한 슬롯머신을 선정할 수 있다.
- 각 슬롯머신에 대하여 현재까지 당첨된 횟수, 당첨되지 않은 횟수를 a, b에 대입하여 베타 분포를 구한다.
- 각 베타 분포의 하단 영역 내에 임의의 x값을 선정한다.
- 각 베타 분포의 임의의 x값 중 가장 큰 값을 갖는 슬롯머신을 시도해야 할 슬롯머신으로 선정한다.
- 선정된 슬롯머신에 대해 시도한 결과를 반영하여 1번의 단계부터 반복한다.
위의 과정 중 2번째 단계를 살펴보면 아래 그림과 같이 구해진 베타 분포에서 하단 영역 내의 임의의 x값을 선정하여 당첨 횟수에 따라 각 슬롯머신별로 당첨될 가능성을 구할 수 있다.
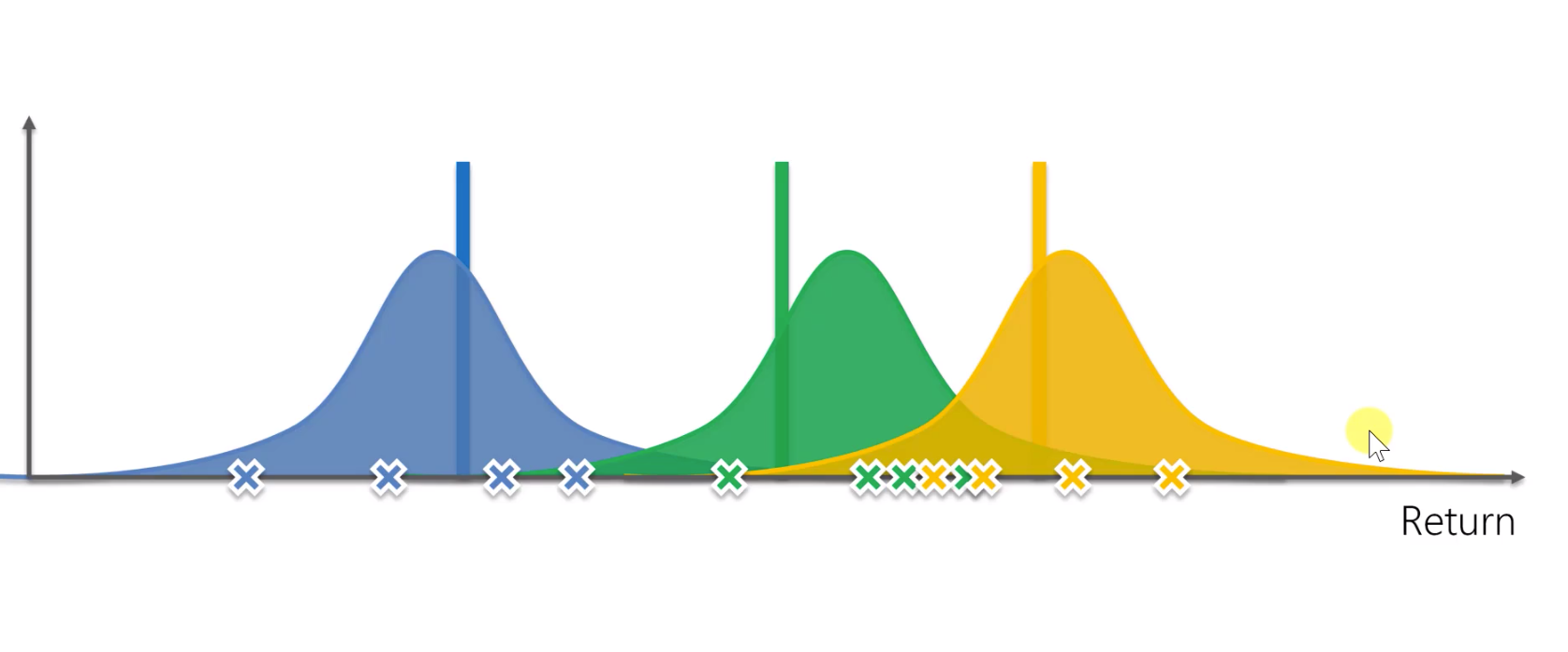
이를 이용하면 자연스럽게 탐색과 지식 활용이 적용되므로 점진적으로 최적의 슬롯머신을 선택할 가능성이 높아진다.
이렇게 TS를 활용하면 어렵지 않게 모든 슬롯머신에 대해 A/B 테스트를 진행할 수 있으며 좋은 성능을 보이는 UCB보다도 더 좋은 성능을 보인다고 한다.(TS 성능 참고)
이 과정을 파이썬으로 간략히 개발해두었으니 파이썬 샘플을 참고하도록 하자.
사용자 세그먼트
앞에서 TS-MAB를 활용하면 베르누이 분포를 갖는 문제에 대하여 쉽게 최적의 해를 구할 수 있다는 것을 확인하였다. 광고 소재를 최적화하는 문제도 베르누이 분포를 가지는 문제라고 볼 수 있기 때문에 TS-MAB를 이용하여 최적화를 진행할 수 있다. 실제로 광고 소재 최적화에 TS-MAB를 적용해보았을 때 꽤 만족스러운 효과를 보였다.
여기서 만족해도 좋지만 더 좋은 효율을 위해 사용자 세그먼트 정보를 활용하는 것이 좋다. 이미 회사 서비스에서는 추천 시스템에서 사용하는 사용자 세그먼트 정보가 있었기 때문에 사용자 세그먼트별로 광고 소재를 최적화하면 더 효과가 있을 것으로 판단하고 사용자 세그먼트 정보를 활용하여 광고 소재 최적화를 진행해보았다.
사용자 세그먼트 정보로는 성별, 연령, OS 정보(iOS, Android, Web 등)와 같은 기본적인 정보 뿐 아니라 별도의 feature를 생성하기도 하였다. 이렇게 사용자 세그먼트를 활용하여 TS-MAB를 진행한 결과 그렇지 않았던 경우보다 2.5배 이상 성능이 개선되었다. 특히 OS 정보는 간단하면서도 뚜렷한 성능 개선 효과를 보였다.
시스템 구조
전체적인 시스템 구조는 아래의 그림과 같다.
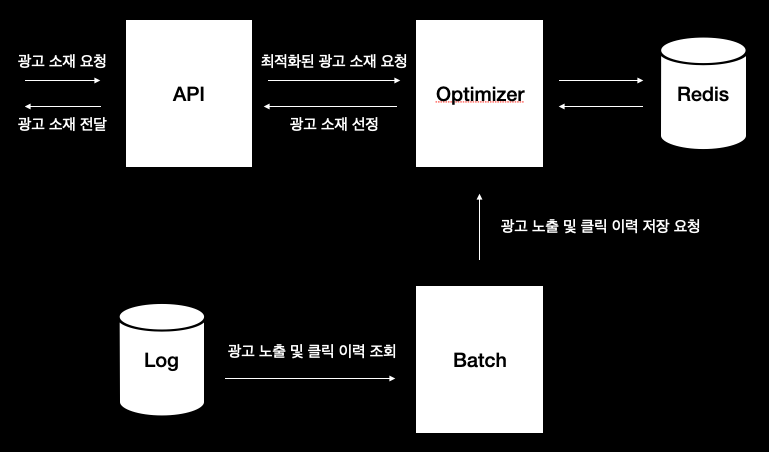
로그 정보를 이용하여 광고의 노출과 클릭 수를 추출하고 추출된 정보를 Optimizer(광고 소재 최적화 서비스)에 전달하여 Redis에 저장한다. 최적화된 광고 소재를 요청할 때는 API에서 가능한 광고 소재 후보들을 전달하고 후보들 중 가장 적절한 광고 소재를 선정하여 전달한다. 이 때 통신은 빠르게 처리하기 위해 gRPC를 활용하였다.
마치며
지금까지 MAB를 이용하여 광고 소재 최적화를 처리한 과정에 대하여 살펴보았다. TS-MAB는 간단하면서 높은 정확도를 보여주었으며 사용자 세그먼트 정보를 활용하여 더 좋은 결과를 얻을 수 있었다.