
실시간(near-realtime)으로 동일한 이미지 찾기
개인이 자유롭게 상품을 올릴 수 있는 중고거래 서비스에서는 판매 금지 상품, 동일 반복 상품, 사기 상품 등 다양한 거래 부적합 상품으로 인한 문제가 발생하곤 한다. 이런 문제를 해결하기 위해 상품이 등록될 때마다 사람이 직접 모니터링을 하고 처리할 수 있지만 효율적으로 처리하기 위해 거래 부적합 상품의 이미지와 동일한 이미지의 상품이 등록되었는지 확인하는 기능이 필요하다. 이 글에서는 동일한 이미지를 찾을 수 있는 다양한 방법들을 소개하고 각각 성능을 비교하여 적용한 후 좋은 효과를 보인 방법에 대하여 설명한다.
전제조건
이미지를 비교하기 앞서 각 이미지는 다음과 같은 전제조건을 만족한다고 가정한다.
- 이미지의 크기는 모두 같다.
- 회전, 리사이징 등의 물리적인 이미지 변형은 없다.
요구사항
동일한 이미지를 찾는 방법에는 여러가지 방법이 있지만 아래의 요구사항을 만족할 수 있는 방법이어야 한다.
- 신규 등록한 상품의 이미지를 비교하기 때문에 매우 빠른 처리속도(near-realtime)를 보여야 한다.
- 동일하지 않은 이미지를 선정하는 것은 괜찮지만, 동일한 이미지를 발견하지 못하는 경우가 없어야 한다. 즉, 정밀도(precision)보다는 재현율(recall)이 더 중요하다.
해당 작업은 단순히 두 이미지를 비교하는 것이 아니라 수많은 거래 부적합 상품 이미지들과 신규 등록한 상품의 이미지를 비교해야 하기 때문에 빠른 속도로 처리되어야 한다. 그러므로 거래 부적합 상품 이미지 원본을 매번 조회해야 하거나 비교하는 과정이 느려서는 안된다. 또한, 일정 수준 이상의 정확도를 가지면서 false negative(동일한 이미지인데 동일한 이미지가 아니라고 판단한 경우)가 있어서는 안된다.
이미지 유사도를 계산하는 방법
이미지 유사도를 계산하기 앞서 이미지 데이터가 어떻게 구성되는지 알아볼 필요가 있다. 이미지 데이터는 색을 표현하는 픽셀(pixel)이라고 하는 조그마한 단위의 데이터를 2차원 공간(가로 길이 * 세로 길이)에 나열한 것이다. 이를 코드로 표현하면 각 픽셀의 색을 표현하는 값을 2차원 배열로 표현할 수 있다. 픽셀의 색상을 표현하는 방법은 다양한데(흑백, RGB, HSV), 흑백일 때는 0~255의 단일 값(스칼라)으로 표현할 수 있고 RGB의 경우는 단일 값으로 표현하기 어려우므로 (255, 0, 0)과 같은 벡터로 표현할 수 있다.(RGB로 표현하면 3차원 배열이 된다.)
2차원 배열로 구성된 이미지의 유사도를 비교할 때 같은 위치의 픽셀 값, 전체적인 픽셀 구조(인접해있는 픽셀 값의 변화량, 이미지 밝기, 대비 등), 색 분포 등 다양한 기준을 비교하여 두 이미지의 유사도를 계산할 수 있다. 이 글에서 다룰 이미지 유사도를 계산할 수 있는 방법은 아래의 5가지 방법이다.
- 히스토그램
- MSE
- SSIM
- imagehash
- LSH
1. 히스토그램
히스토그램은 값들의 도수 분포를 나타낸 것으로 이 작업에서는 이미지를 구성하는 픽셀의 색 분포 히스토그램을 비교하여 유사도를 구할 수 있다. 히스토그램을 이용하면 이미지를 구성하는 픽셀의 전반적인 색 분포를 알 수 있기 때문에 픽셀의 위치이나 구조를 고려하지 않고 유사도를 측정가능하다.
이 방법은 하늘 이미지는 하늘색, 숲이나 산 이미지는 초록색 분포도가 도드라지듯이 색이 도드라지는 이미지의 유사도를 분석할 때는 의미가 있으나 다른 사물의 이미지임에도 유사한 색 분포를 보일 수 있고 픽셀 위치나 구조를 고려하지 않고 색 분포만을 고려하기 때문에 비교적 정확성이 떨어진다.(바나나와 병아리가 노란색 분포가 많아 동일한 이미지라고 판단할 가능성이 큰 것과 같다.)
2. MSE(mean square error)
MSE(mean square error)는 이미지의 유사도를 계산할 때 가장 쉽게 생각해볼 수 있는 방법으로, 두 이미지의 각 픽셀간 거리(차이)를 평균내어 유사도를 파악한다. 계산하는 방법은 아래 수식과 같다.
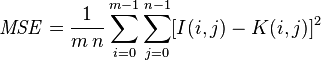
수식을 보면 m * n의 크기를 가지는 I와 K 이미지의 모든 픽셀에 대해서 제곱 오차(square error)를 구하고, 이 제곱 오차의 평균을 내어서 두 이미지의 유사도를 계산한다.
이 방법은 동일 위치의 픽셀 차이를 계산하여 정확하게 유사도를 구할 것 같지만, 픽셀간의 제곱 오차가 상대적인 수치를 나타내지 않고(100과 50의 차이와 200과 150의 차이가 둘다 50이므로 같은 차이라고 판단), 이미지의 픽셀 구조를 계산할 수 없기 때문에 이미지의 유사도를 정확히 계산하기 어렵다.
3. SSIM(structural similarity index)
SSIM(structural similarity index)는 MSE의 문제를 해결하기 위한 방법으로 이미지를 구성하는 픽셀의 구조를 비교한다. 계산 방법은 아래의 수식과 같이 계산한다.
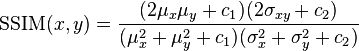
수식에 대한 설명은 structural similarity를 참고하면 된다.
수식의 의미를 간단히 설명하자면, SSIM은 밝기, 대비, 구조를 고려한 이미지의 유사도를 구하는 방법으로 픽셀의 평균으로 이미지의 밝기를, 표준편차를 이용하여 대비를, 공분산(covariance)를 이용하여 인접 픽셀의 변화량의 비례, 반비례 여부를 구한 후 유사도에 반영한다.
아래 그림을 보면 대비 값이 변경된 두 이미지의 유사도를 볼 수 있다.
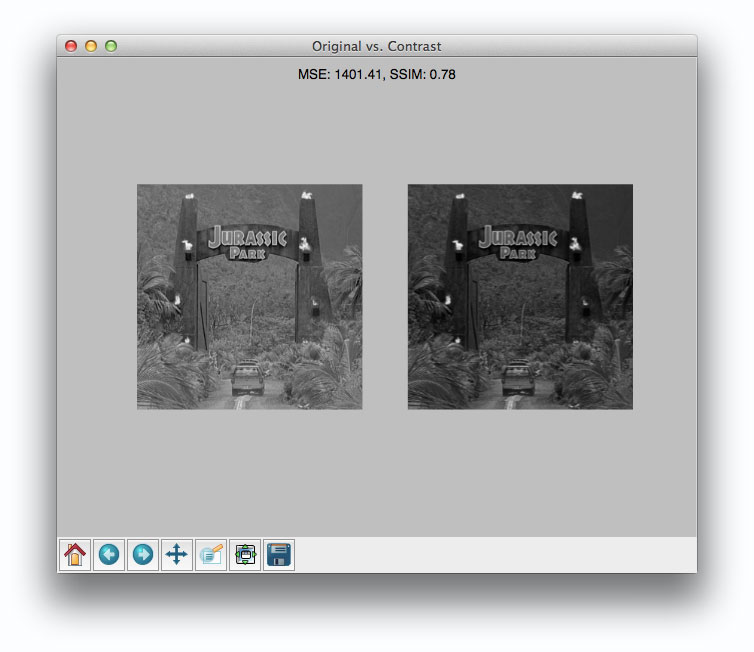
유사한 이미지로 보이는 두 이미지의 MSE가 매우 큰 것을 확인할 수 있는데 이는 왼쪽 이미지에 대비를 조절한 오른쪽 이미지가 각 픽셀마다 +@의 값이 변경되기때문에 MSE가 큰 것으로 볼 수 있다. 반면, SSIM은 픽셀의 구조를 비교하기 때문에 1에 가까운 0.78이라는 수치를 보여 더 정확한 비교가 가능하다.
4. imagehash
imagehash는 이미지에 고유한 fingerprint를 부여하기 위해서 다양한 방법으로 압축한 이미지를 해시 함수를 이용하여 대표할 수 있는 하나의 값으로 변환하는 방법이다.(사실, imagehash와 뒤에 설명한 LSH는 대표값을 만드는 것보다 어떻게 이미지를 압축할 것인가에 대한 방법이다.)
imagehash에는 크게 3가지 방법이 있다.
- average hash
- perceptive hash
- difference hash
average hash는 정해진 사이즈로 압축한 이미지의 각 픽셀 값을 평균 값과 비교하고 그 결과를 해시하는 방법이다. average hash는 빠르고 쉽지만 전반적인 평균 값을 보정하는 경우 정확도가 떨어진다.(학생들의 평균 성적이 80점에서 90점이 되더라도 모든 학생의 성적이 올랐으므로 평균보다 더 높은 성적을 받은 학생의 수는 크게 변하지 않는 것처럼)
perceptive hash는 average hash의 단점을 보완한 방법으로 DCT(discrete cosine transform)를 이용한다. DCT는 손실 이미지 압축에 많이 사용되는 방법으로 낮은 주파수 영역(색상이 유사한, 더 특징적인, 더 유의미한)을 추출하여 유의미한 값으로 이미지를 압축시킬 수 있다. 이렇게 압축된 이미지는 average hash를 위해 단순 압축된 이미지보다 유의미하기 때문에 더 좋은 성능을 보일 수 있다.
difference hash는 정해진 사이즈로 압축한 이미지의 인접해있는 픽셀의 값의 크기를 비교하는 방법이다. average hash와 perceptive hash가 값 자체를 평가한다면, difference hash는 픽셀간의 변화량을 평가한다.
각 imagehash는 단순 압축, DCT를 이용한 압축, 압축한 이미지의 인접 픽셀 변화량을 이용하여 압축된 2차원 배열을 얻을 수 있고, 이 2차원 배열은 Hamming distance algorithm를 이용하여 유사도를 비교를 할 수 있고, 간단한 해시 함수를 통해서 단일 값으로 변환한 후 비교할 때 사용할 수 있다.
imagehash에 대한 자세한 내용은 imagehash 링크를 참고하면 된다.
5. LSH(locality sensitive hash)
LSH(locality sensitive hash)는 Jaccard 유사도가 높은 원소를 같은 버킷에 넣어 차원을 축소하는 해시 알고리즘이다. 이 알고리즘은 유사한 문서나 이미지를 찾거나 할 때 많이 사용되는데, 기본 동작 원리는 커다란 차원의 데이터를 signature matrix로 변환하고 일부러 버킷에 중복이 일어나기 쉬운 해시 함수를 활용하여 유사한 값을 동일한 버킷에 넣어 유사한 값들끼리 같은 버킷에 모일 수 있도록 한다.
LSH가 동작하는 과정은 간략하게 설명하면 아래의 3단계로 처리된다.
- shingling
- min-hashing
- locality-sensitive hashing
shingling은 각 문서의 값들을 ngram을 이용하여 쪼갠 후 sparse matrix로 변환하는 것이다. 이렇게 변환된 값에 대하여 일일히 Jaccard 유사도를 계산하면 시간, 공간 복잡성이 상당하기 때문에 바로 유사도를 계산하지 않는다.
min-hashing은 효율적인 계산을 위해 커다란 크기의 sparse matrix의 크기를 줄이는 방법으로 permutation(index를 이용하여 임의로 섞인 목록)를 이용하여 signature matrix를 구한다. signature matrix는 전체 이미지 개수 * permutation 크기 만큼의 공간을 사용하기 때문에 공간 복잡도가 상당히 줄어든다.
locality-sensitive hashing에서는 signature matrix에서 band partitioning(하나의 문서에 해당하는 컬럼을 적절한 단위로 나누는 작업)을 하고, 나뉘어진 밴드에 대하여 소수의 버킷에 중복하여 할당될 수 있는 해시 함수를 적용하여 유사한 데이터끼리 모일 수 있도록 한다.
LSH가 동작하는 과정을 자세히 알고 싶으면 LSH 링크를 참고하면 된다.
성능 비교
위에서 설명한 5개의 방법을 대상으로 간단한 성능 테스트를 진행하였다. 테스트는 480 * 480 사이즈의 흑백 이미지를 대상으로 진행하였으며, 각 방법의 수행시간(jupyter의 %%timeit 이용)과 정확도를 살펴보았다.

첫 번째 이미지는 대상 이미지, 두 번째 이미지는 대상 이미지와 유사한 이미지, 세 번째 이미지는 대상 이미지에 대비(contrast)를 보정한 이미지, 네 번째와 다섯 번째 이미지는 유사하지 않은 이미지로 테스트 케이스를 구성했다.
테스트에 사용한 코드는 동일 이미지 비교 테스트를 참고하기 바란다.
이 테스트를 진행했을 때 SSIM은 처리 속도가 너무 느렸고, MSE는 비교를 할 때마다 모든 이미지를 조회해야하는 부담이 있었다. 원본 이미지를 매 계산마다 조회해서 처리하는 것은 수천에서 수십만개의 이미지를 비교해야한다고 가정했을 때 적합하지 않은 처리 방법으로 보였다. 또한, 히스토그램은 색 분포만을 고려하기 때문에 정확성을 보장하기 어려웠다.
반면, imagehash는 각 이미지를 축약된 해시 값으로 변경할 수 있기 때문에 elasticsearch와 같은 검색 엔진을 이용하면 쉽고 빠르게 작업을 진행할 수 있다고 판단했다. LSH도 이미지를 의미있게 줄일 수 있는 좋은 방법이었지만, permutation이 바뀌면 모든 signature matrix의 값을 갱신해야 하고, 비교해야 할 이미지의 정보가 삽입되어 있는 minhash 객체를 메모리에 유지시켜야 한다는 점에서 imagehash와 elasticsearch의 조합보다는 효율성이 떨어질 것으로 판단했다.
효율
imagehash + elasticsearch 조합으로 실제 서비스에 적용한 후 약 2년이 지났지만 동일 이미지를 놓친 경우는 아직 발견되지 않았다. 또한, 정확도를 높이기 위해 단일 색상이나 단순 이미지의 경우 비교대상에서 제외하고 3가지 imagehash(average, perceptual, difference) 값이 모두 일치하는 경우로 조건을 개선한 결과 동일한 이미지가 아니지만 동일한 이미지라고 판단한 경우(false positive)는 약 2년 동안 3건 밖에 없었다.(실제로 사람이 봐도 매우 유사하다고 판단되는 경우였다.)
마치며
지금까지 동일한 이미지를 찾을 수 있는 다양한 방법들에 대해 살펴보았다. 여러가지 방법 중 빠른 처리를 위해서는 imagehash와 lsh를 활용하는 것이 좋다. 특히, imagehash는 이미지의 크기를 최소화하여 특정 값으로 치환할 수 있는 방법으로 실시간으로 비교 처리를 해야 하는 작업에 유용하게 사용할 수 있다. 수십만개의 이미지 중 동일한 이미지를 빠르게 찾아야 한다면, imagehash의 결과를 elasticsearch에 색인하여 좋은 효과를 볼 수 있을 것이다. 만약, 동일 이미지를 찾는 것이 아니라 일정 기준 이상으로 유사한 이미지를 찾고 싶다면 imagehash와 LSH를 조합하여 사용하면 좋은 효과를 거둘 수 있을 것이다.